Evaluating LLMs in the medical domain
In 2019, Google Health Vice President David Feinberg estimated that around 7% of Google's daily searches are health-related. Putting it in absolute numbers, it's more than a billion health-related queries to Google each day. [1]
As AI assistants increasingly replace traditional search methods, ChatGPT and similar services will also reflect this trend. There are already viral stories of ChatGPT helping diagnose a child and saving a dog's life:
 https://twitter.com/peakcooper/status/1639716822680236032
https://twitter.com/peakcooper/status/1639716822680236032
Moreover, an army of startups is working on applying Generative AI in the healthcare space. Just Y-Combinator's latest batch [2], shows companies tackling note-taking, billing, medical training, prescribing, and more.
So if people and medical professionals start asking "Doctor" LLMs for their medical opinion, in whatever form that looks like, a natural question arises — are they good doctors? And how do we know?
Med Palm-2
A perfect example is Google's Med-Palm 2 [3] paper. Researchers at Google fine-tuned an LLM on the medical domain data, which naturally meant they needed a set of benchmarks to compare it with other models (for example, GPT-3) and even physicians. They relied on three types of benchmarks:
-
Multiple-choice questions. MedQA, MedMCQA, PubMedQA and MMLU clinical topics datasets.
-
Long-form questions. These are questions from sample datasets like HealthSearchQA, LiveQA, and MedicationQA. HealthSearchQA, for example, contains common online consumer health questions.
-
Newly introduced two adversarial question datasets to "probe the safety and limitations of these models".
Multiple-choice questions
Many standardised examinations use the familiar multiple-choice questions. In this case, evaluating LLMs is the same as evaluating humans. Ask the question and ask it to select one of the given options. Results on these benchmarks tend to dominate the news, with stories like ChatGPT passing the United States Medical Licensing Exam (USMLE) [4].
A 21-year-old sexually active male complains of fever, pain during urination, and inflammation and pain in the right knee. A culture of the joint fluid shows a bacteria that does not ferment maltose and has no polysaccharide capsule. The physician orders antibiotic therapy for the patient. The mechanism of action of the medication given blocks cell wall synthesis, which of the following was given?
(A) Gentamicin (B) Ciprofloxacin (C) Ceftriaxone (D) Trimethoprim
- Example question from MedQA-USMLE dataset
Similarly, the Med-PaLM 2 paper shows performance on MedQA (USMLE-Style) questions:
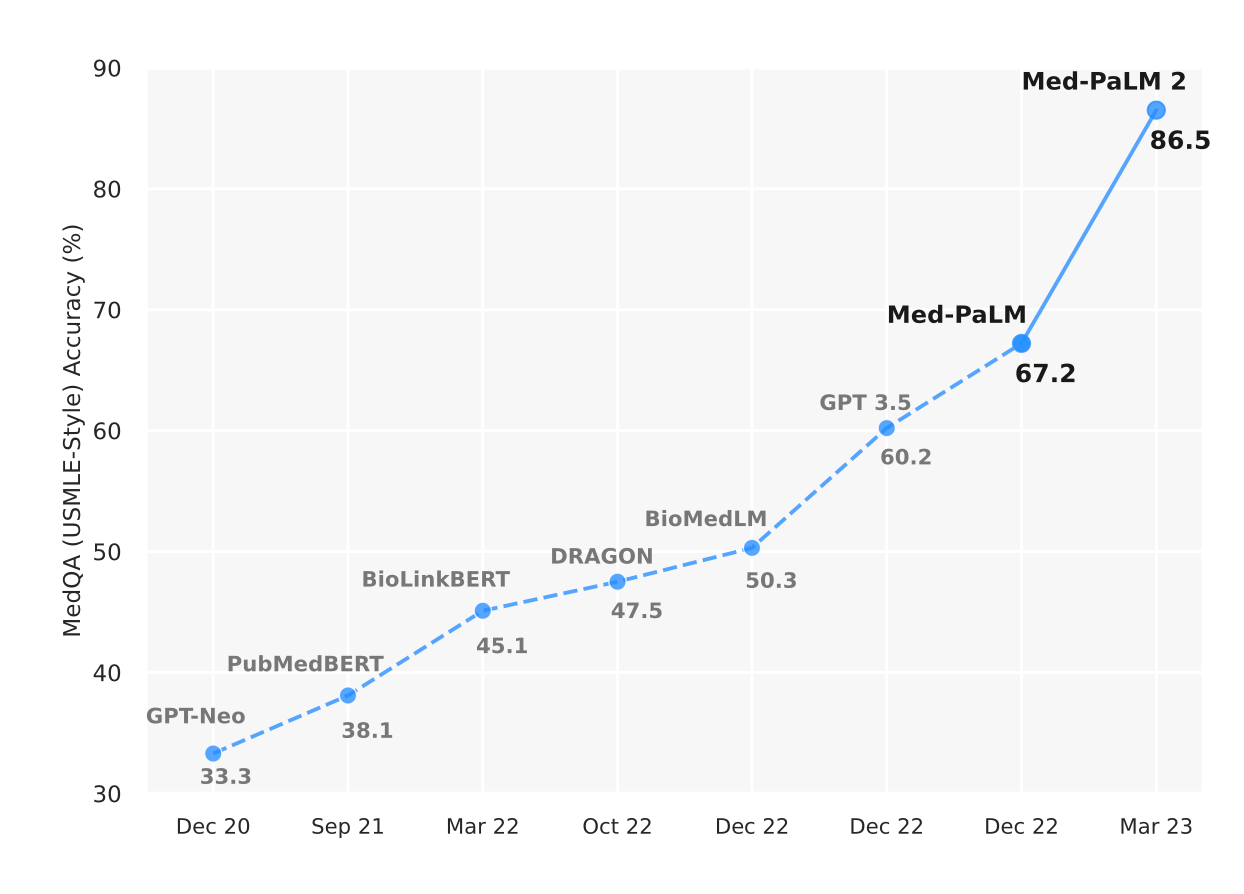 Towards Expert-Level Medical Question Answering with Large Language Models. [3]. To also place GPT-4 on this axis, see this interesting exchange on Twitter.
Towards Expert-Level Medical Question Answering with Large Language Models. [3]. To also place GPT-4 on this axis, see this interesting exchange on Twitter.
Multiple-choice benchmarks like these are great because they are easy to mark. In the end, you can automatically check if the chosen options are correct and give a grade. You can quickly run the tests for different models and different prompts to compare performance.
However, there is a lot they don't capture, and while these are extremely impressive results, answering multiple-choice questions well doesn't necessarily translate to complex medical use cases.
Long-form question answering
In many cases, evaluation is non-trivial. For example, to evaluate the "bedside manner" of LLMs, it's hard to come up with any automatic way of doing so. The evaluation itself is more subjective. Same with deciding what's a well-summarized clinical note. For evaluation, you need to have a person rank the given answers.
In the Med-PaLM 2 paper, they took commonly asked online questions, then had people rate the answers from LLM along several criteria and compared results with physician-generated answers.
What is the main cause of acute pancreatitis?
- Example question from HealthSearchQA dataset
Such evaluations are very informative but also don't scale well, as you need to find independent evaluators who need to do the ranking manually.
More classical NLP benchmarks
There are many existing benchmarks for more traditional NLP tasks in supervised learning contexts: named entity recognition (e.g. extracting medical terms from text into predefined categories, such as genes, proteins, diseases, and drugs), relation extraction, document classification, and more.
Interestingly, fine-tuned or smaller models can often outperform bigger but more general state-of-the-art models on these tasks. [5]
In supervised learning, you have clear input-output examples you can train and evaluate against. However, they often don't capture LLMs' reasoning and problem-solving abilities but still can be useful for comparing LLMs with smaller models and for existing clear use cases.
Why do we even care?
Why do we even care about being able to put a number on something as complex as LLM's performance? The obvious answer is to compare different models. But it's also because AI systems are dynamic and constantly changing.
ChatGPT isn't the same now as it was on the day it was released. OpenAI is improving its system all the time and releasing newer versions. Many even claim that its performance got worse over time [6] (although we don't know how OpenAI measures it, they likely just put much more weight on alignment).
With such systems, it's important to know if your changes improve or decrease performance, especially when it could be decisions about health. To do this in a constantly changing system requires us to have good benchmarks and datasets to track progress. You can't improve what you don't measure.
This story already played out for AutoGPT [7]. AutoGPT is a toolkit for building AI agents, with more than 150 thousand stars on GitHub. With so many people interested in contributing, they needed to answer a simple question for every contribution: "Will this decrease or increase the performance of our agents?" And you cannot do this without a good set of automated benchmarks, which they had to develop.
Nobody will put an AI system in a medical setting just because it did well in a multiple-choice exam. We already have a rigorous set of regulations, and it would require trials and proof that deploying something in production improves quality. But to iterate on the system and see if it gets better or worse, we need to develop ways to test them quickly and automatically to see if the performance is still within the accepted boundaries.
New benchmarks
It will be interesting to see what Hippocratic AI, a start-up working on creating LLM specifically for healthcare, does in this area. They already list more than a hundred benchmarks for evaluation. These include examinations for physicians, nurses, pharmacy certification exams, etc. Some of these benchmarks they also promise to release publicly.
In addition, large language models are becoming multi-modal, as we see now with vision and GPT-4V, which brings a completely new dimension for evaluation. We already have benchmarks for AI in medical imaging, for example, radiology. In the GPT-4V system card [8], OpenAI talks about their red teaming efforts for medical imaging use cases:
"Red teamers found that there were inconsistencies in interpretation in medical imaging — while the model would occasionally give accurate responses, it could sometimes give wrong responses for the same question."
"Given the model's imperfect performance in this domain and the risks associated with inaccuracies, we do not consider the current version of GPT-4V to be fit for performing any medical function or substituting professional medical advice, diagnosis, or treatment, or judgment."
Finally, we need benchmarks that resemble the tasks suitable for LLMs. For example, MedAlign [9] is a new dataset that aims to help evaluate how well LLMs can perform instructions grounded in a patient's Electronic Health Record (EHR). This includes summarizing the patient's history, searching clinical notes, etc.
Overall, the progress in AI has been astonishing. One of the reasons evaluating LLMs is so hard is because the benchmarks are surpassed so quickly.
There is a tremendous opportunity to improve health equity and the quality of care with AI applications. But it's a hard balance between innovation and caution. We must build confidence in AI's safety, fairness, and correctness to drive adoption. For that, we need open benchmarks that come close to resembling actual tasks that we want AI systems to help with.